ChatGPT:
How Sound Becomes Meaning: From Ear to Brain
This podcast episode from From Our Neurons to Yours explores how human brains transform mere sound waves into meaning, especially when processing speech. Neuroscientist Laura Gwilliams explains the journey of sound from the outer ear to complex comprehension, highlighting the remarkable biological and neural systems that allow us to interpret language quickly, automatically, and often unconsciously.
Conclusion (Final Insights)
Sound becomes meaning through a multi-stage, bidirectional process starting with air pressure fluctuations hitting the eardrum and ending in neural comprehension of speech and ideas. Vibrations are amplified by middle-ear bones and processed by hair cells in the cochlea, which sort sound by frequency. This mapping is preserved in the brain’s auditory cortex. Humans then use both acoustic input and contextual knowledge to make sense of speech, even when parts are missing. Unlike AI systems that need huge data sets, human brains, even those of young children, are highly efficient in understanding language due to pre-wired evolutionary architectures. Speech comprehension reveals deeper truths about how the brain stores and manipulates concepts, making it a key window into the human mind.
Key points (Claves del contenido)
🧠 Hair cell tuning: The cochlea contains frequency-tuned hair cells that sort incoming sound by pitch, forming a “map” sent to the brain.
⚡ Analog to digital: Vibrations are converted to electrical signals via the auditory nerve, then processed through brainstem, midbrain, thalamus, and cortex.
🗣️ Cortical frequency mapping: The frequency layout from cochlea is mirrored in auditory cortex, aiding pitch recognition and processing.
🧬 Universal phoneme perception: Infants can perceive sounds from all languages, but this ability narrows with language exposure by adulthood.
🔠 Higher-level processing: Beyond the auditory cortex, adjacent regions finely tune to speech-relevant features like distinguishing “P” vs “B” sounds.
⏱️ Temporal buffering: The brain holds onto auditory information for up to a second, aiding in complex comprehension like linking pronouns to earlier references.
🔄 Bidirectional understanding: Perception fuses bottom-up sound input with top-down expectations, letting context disambiguate missing or unclear words.
🧒 Efficiency of human learning: Unlike AI, children need far less data to achieve language comprehension, suggesting innate evolutionary “pre-training.”
📲 Brain vs AI: Speech tech like Siri and Alexa mimic comprehension but are less efficient, needing vast data and lacking human-level contextual understanding.
🗯️ Speech = cognitive window: Studying speech reveals how the brain represents, manipulates, and accesses meaning, offering insights into broader mental processes.
Summary (Resumen del contenido)
Speech shows cognitive architecture: Speech comprehension reflects how the brain structures thought, making it a unique lens into the human mind.
Speech starts as air pressure: Sound begins as pressure changes in the air that vibrate the eardrum and are amplified by tiny bones in the middle ear.
Cochlear hair cells detect pitch: These cells are organized along the cochlea to vibrate preferentially to specific frequencies, like high or low sounds.
Auditory nerve converts signal: Once vibrations reach the cochlea, hair cells convert them into electrical impulses that travel to the brain.
Auditory cortex mirrors cochlea: In the brain, pitch-sensitive neurons form a frequency gradient that parallels cochlear layout, aiding tone perception.
Speech specialization emerges: Higher-order regions next to the auditory cortex respond more precisely to speech than to general sound.
Language learning is time-sensitive: Children can learn all sound distinctions, but if exposure occurs too late (e.g., after age 30), certain sounds can’t be distinguished.
Processing is layered and parallel: The brain handles multiple levels of linguistic information—phonemes, syllables, meaning—simultaneously.
Expectation aids interpretation: We use learned context and expectations to fill in gaps, especially in noisy environments or interrupted speech.
Temporal memory bridges meaning: The brain keeps auditory info for seconds, helping link ideas across distant parts of speech or sentences.
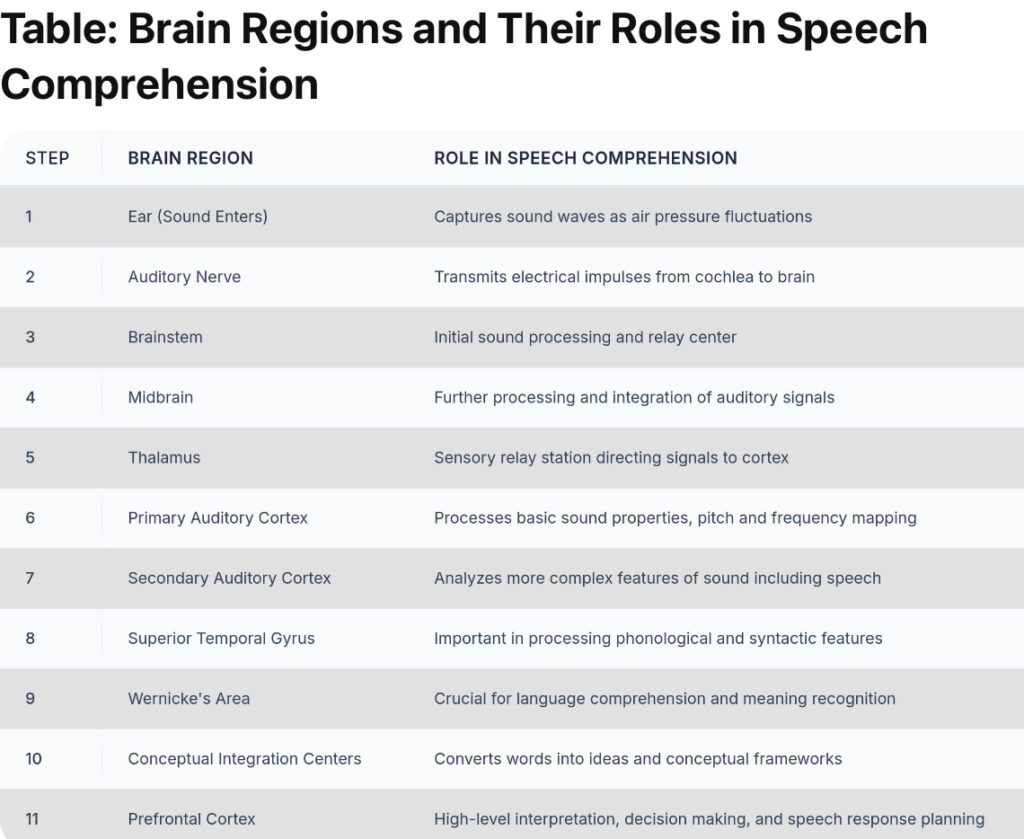
What is the process of turning sound into meaning in the human brain?
The journey begins with sound waves entering the ear, vibrating the eardrum, and being amplified by the ossicles. These vibrations stimulate hair cells in the cochlea, which are frequency-specific. The signals then convert to electrical impulses that travel via the auditory nerve through the brainstem and thalamus to reach the auditory cortex, where the brain begins decoding sound into meaningful language.
How does the cochlea help with sound processing?
The cochlea contains hair cells that are arranged tonotopically—meaning each location responds to specific frequencies. High-pitched sounds are processed at the base, and low-pitched sounds at the apex. This pitch map is preserved in the auditory cortex, allowing the brain to analyze complex sounds.
How does the brain distinguish between similar speech sounds like “p” and “b”?
Specialized regions next to the auditory cortex are highly sensitive to subtle acoustic features crucial for distinguishing speech sounds. These areas are more finely tuned than general auditory regions and play a key role in identifying phonemes like “p” vs. “b.”
Can adults learn to hear all speech sounds from other languages?
Adults struggle to perceive phonemic contrasts not present in their native language if they weren’t exposed early in life. This is due to the brain’s reduced plasticity with age, which makes acquiring new auditory distinctions much harder.
What role does context play in speech comprehension?
Context helps the brain fill in missing or unclear information. Expectations from prior knowledge or ongoing conversation guide interpretation, allowing people to understand speech even when parts are masked by noise.
How does the brain hold on to sounds over time?
The brain temporarily retains auditory information for hundreds of milliseconds to link distant elements of speech, like pronouns to earlier nouns. This temporal buffering is crucial for understanding complex sentence structures.
Is speech processing automatic or conscious?
Speech comprehension is highly automatic. People typically cannot stop understanding language once it’s heard. This fast and involuntary nature reflects the brain’s deep specialization for language.
Why is speech a useful window into the mind?
Studying speech reveals how the brain encodes and manipulates abstract concepts. Because language is a key way we express thoughts, examining its neural basis provides insight into cognition, memory, and emotion.
How do children learn language so efficiently compared to AI systems?
Children acquire language from relatively limited exposure, suggesting humans have innate neural architectures for language learning. In contrast, AI systems need massive datasets and still lack human-level contextual understanding.
How is human speech comprehension different from how Alexa or Siri works?
AI systems rely heavily on large-scale data and pattern recognition, lacking the biological efficiency and contextual integration humans use. Human brains are more adaptive and require less data for fluent understanding.
The difference between human speech comprehension and AI speech recognition models lies in efficiency, adaptability, context integration, and biological architecture. Here’s a breakdown:
1.
Data Efficiency
- Humans: A child can understand and produce language after just a few years of exposure, with relatively limited examples. This suggests innate, evolutionarily shaped structures that are pre-wired to learn language efficiently.
- AI Models: Systems like Siri, Alexa, or ChatGPT require massive datasets—millions of hours of labeled speech and text—to achieve comparable performance. They are not born with any “pretraining” unless engineered with it.
2.
Contextual Understanding
- Humans: Use top-down expectations (e.g., prior knowledge, conversational context, social cues) to disambiguate unclear speech. If a loud noise covers a word, humans can still guess it from context.
- AI Models: Generally rely on statistical probabilities from training data. They may fail to correctly interpret ambiguous or incomplete input unless explicitly trained on similar patterns.
3.
Parallel & Dynamic Processing
- Humans: Process multiple levels of language simultaneously and over time—from raw sound, to phonemes, to meaning, while also holding previous words in memory.
- AI Models: Often process text or audio in sequential chunks. While models like transformers can consider some history, they don’t maintain memory or dynamics the way brains do.
4.
Biological vs Statistical Architecture
- Humans: The brain has specialized areas for sound, pitch, meaning, and grammar. It retains information briefly (up to 1 second) to form cohesive understanding.
- AI Models: Based on layers of artificial neurons optimized through gradient descent. They simulate language understanding but do not replicate the biological functions or time dynamics of a brain.
5.
Creativity and Meaning
- Humans: Can generate entirely novel ideas, metaphors, and associations with ease. A weird sentence like “I rode a cactus to work over the clouds” instantly creates a mental image.
- AI Models: Can generate creative text but lack internal experience, imagination, or understanding of what words actually feel like. Their “creativity” is recombination, not intuition.
In summary:
Humans understand speech naturally, contextually, and adaptively—AI mimics this through massive training, but lacks the biological and experiential grounding.