

ChatGPT:
🤖📚
“It Sounds Right, So It Must Be Wrong:”
Why LLMs Are So Confidently Dumb (And How to Outsmart Them)
Large Language Models (LLMs) like GPT, Claude, and their alphabet-soup cousins are amazing. They can write poems, generate code, draft emails, and summarize your favorite conspiracy theory with suspicious enthusiasm.
But sometimes they get things hilariously wrong.
Worse, they sound really smart while being wrong.
Here’s why that happens, what you can (and can’t) do about it, and how to tame the hallucinating beast.
🧠 1. Why LLMs Prioritize
Coherence
Over
Accuracy
Let’s start with the root of the problem:
LLMs are built to predict, not to know.
- Their job is to guess what comes next in a sentence.
That’s it. The whole architecture is designed to say:
“Given this text, what’s the most likely next word?” - They’re trained on mountains of human writing.
Which includes:
- Facts ✅
- Opinions 🤷♀️
- Fiction 🧚♂️
- Reddit posts 🚩
- Fanfiction involving dragons and Supreme Court justices 😬
- Coherence is their only compass.
They don’t care if something is true — they care if it sounds like it belongs in the sentence.
So if you ask:
“Did Napoleon invent the microwave?”
They might say:
“Napoleon is credited with many innovations, including the early development of microwave-based food heating devices.”
Because it feels like the right kind of sentence.
(And because humans say weird stuff on the internet.)
✅ 2. Can LLMs Be Made to Prioritize Accuracy?
Not perfectly. But yes, there are ways to nudge them toward being less wrong.
Here’s how:
✔️ Feed them better inputs
Give them trusted documents and say:
“Only use this as your source. Do not make anything up.”
This is called retrieval-augmented generation (RAG).
It works… unless the model gets creative anyway.
✔️ Prompt them carefully
The prompt matters more than your job title. If you say:
“Summarize this study”
They might hallucinate a conclusion.
But if you say:
“Only summarize what’s explicitly stated. Do not infer or invent.”
You get a much safer output.
✔️ Lower the “temperature” (if using the API)
A lower temperature setting = less creative, more boring = better for factual stuff.
It’s like turning down the AI’s artistic license.
🚨 3. Real-Life Examples Where Coherence Destroyed Truth
Here’s what happens when LLMs go full confidence, zero accuracy.
🔍
Fake Citations
Prompt: “Give me studies proving honey cures cancer.”
Output: Perfectly formatted, totally fabricated citations from journals that don’t exist.
Coherence: 10/10
Truth: -200
📜
Imaginary Laws
Prompt: “Can I marry my couch in California?”
Output: “California Civil Code §742.8 does not currently allow marriage between a human and an object.”
Looks legit. Sounds lawyer-y.
The law doesn’t exist. The section doesn’t exist.
But the couch might still say yes.
📖
Fictional Book Summaries
Prompt: “Summarize the book The Wind and the Lantern.”
Output: A beautiful paragraph about a young girl navigating grief in a post-industrial lighthouse town.
Problem?
That book doesn’t exist. The model just invented the plot based on the title.
🧰 4. How to Trick LLMs Into Being Less Wrong
(This section is the real money-maker.)
If you want your AI to stop gaslighting you with poetic nonsense, here’s how to take control:
🧷
1. Use “Don’t Guess” Clauses
Prompt:
“If the answer is unknown, say ‘I don’t know.’ Do not make something up.”
LLMs default to always answering.
Giving them permission to say “I don’t know” frees them from improv duty.
🧱
2. Restrict to Provided Sources
Prompt:
“Only use the information in the article below. Do not add external knowledge.”
This tells the model: Don’t go outside. It’s dangerous out there.
🧠
3. Say: “Think step by step.”
Chain-of-thought prompting helps LLMs reduce logical errors by slowing them down.
Instead of:
“What’s 42 x 93?”
Try:
“Let’s solve 42 x 93 step by step.”
Magically, it remembers how math works. Sometimes.
📚
4. Ask for Sources — Then Actually Check Them
Prompt:
“Include the name of the study and where it was published. No made-up sources.”
Then cross-reference. If it gives you:
“A 2015 study from the Journal of Advanced Quantum Bread Science…”
That’s your clue.
🚫
5. Warn Against Fiction
Prompt:
“Only respond if this book/person/law actually exists. If not, say so.”
This is like putting up guardrails. Or at least a “No Trespassing” sign on the edge of fiction.
🪬
6. Add Identity Constraints
Prompt:
“You are a helpful AI trained to avoid hallucinating or making things up.”
Weirdly, reminding the model of its purpose can shape its behavior.
Like telling your dog, “You’re a good boy” — and hoping he doesn’t eat drywall.
🧠 TL;DR — Trust but Verify
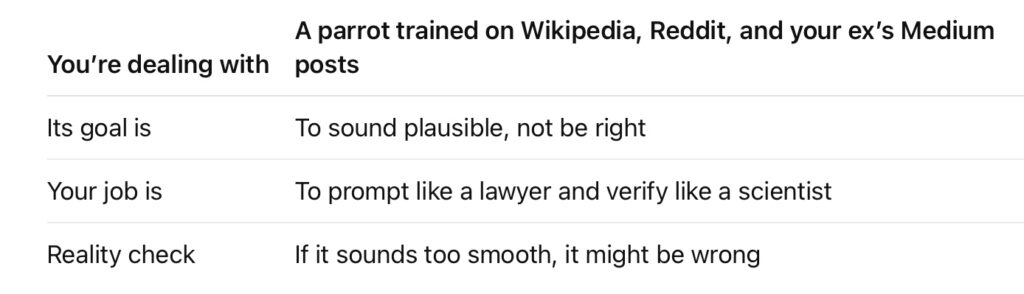
Want truth from your AI? You’re going to have to build the fences yourself.
Because left alone, it will happily write a Nobel Prize speech for a toaster and cite a fake journal about honey-based chemotherapy.
Now you know how to fight back. Good luck out there, truth wrangler.